Boosting Bulk Request Performance in Data247 with Asyncio
Boosting Bulk Request Performance in Data247 with Asyncio
The Challenge with Bulk Requests
At Data247, we help clients efficiently handle large amounts of data through bulk requests. These requests bundle many smaller queries into one, reducing network overhead and boosting server performance. But even with optimization, the latency (processing time) for individual requests could still be high. Let's dive into how we tackled this using Python's asyncio library.
Initial Backend Processing Approach
Our backend already used asyncio for efficient asynchronous programming. This means that even though we only have one CPU thread, it could juggle multiple requests and cleverly switch between them when waiting for things like data to be sent or received.
The problem was that the individual queries were still processed one after the other within a single bulk request. We weren't fully taking advantage of the CPU's potential.
The Solution: Concurrent Coroutines
The key to further improvement was to split the execution of a single bulk request into multiple coroutines (think of them as lightweight tasks) that could run concurrently. This is where the asyncio.gather() function comes in.
How I used Asyncio gather()
Break it Down: Instead of processing queries in a strict sequence, we create a coroutine for each individual query within a bulk request.
Gather 'Em Up: We collect these coroutines into a list and hand them to asyncio.gather().
Work in Parallel: asyncio.gather() allows all these coroutines to run at the same time, making the most of our CPU resources.
Collect the Results: Once all the coroutines have finished, we retrieve the results and combine them into the final response.
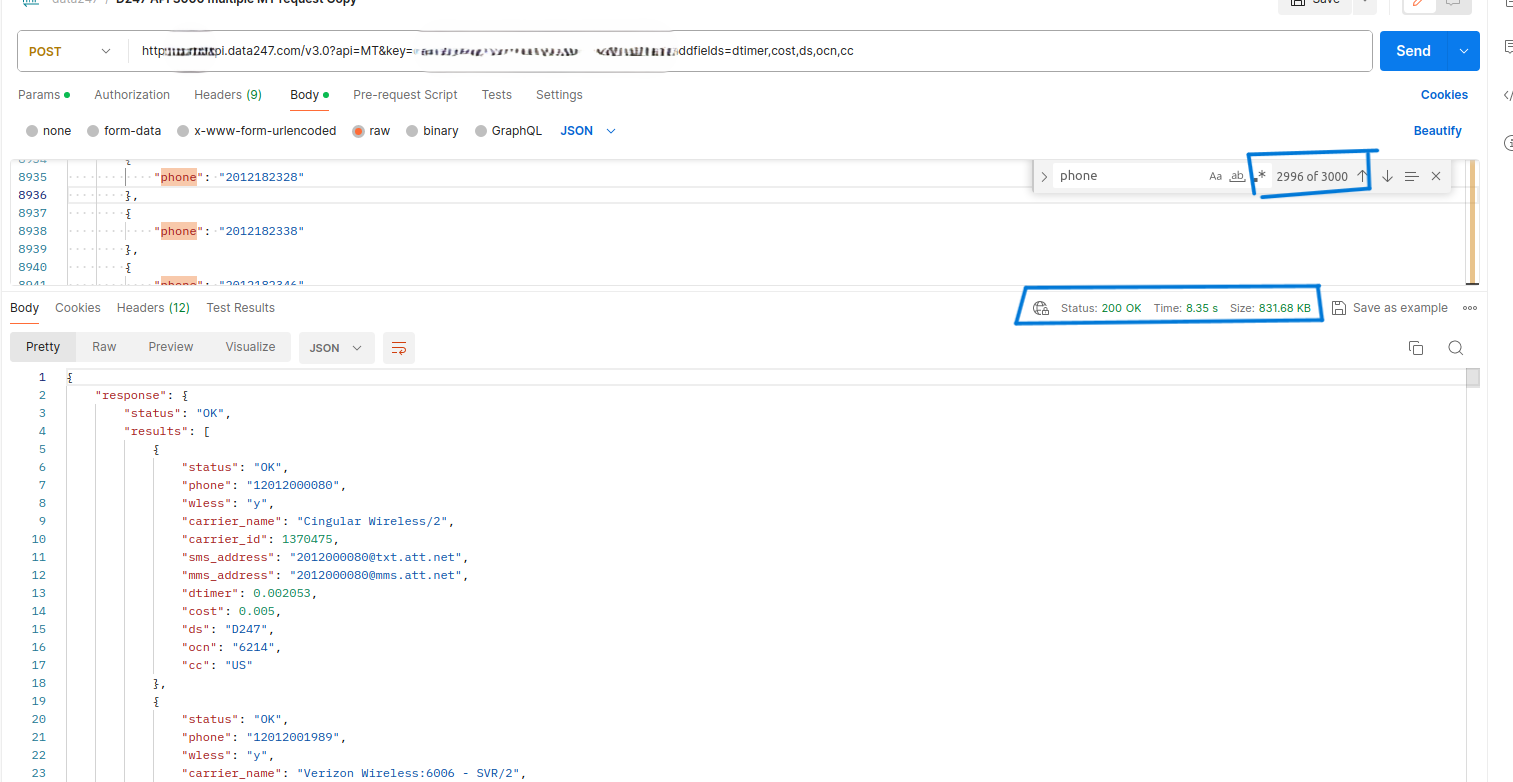
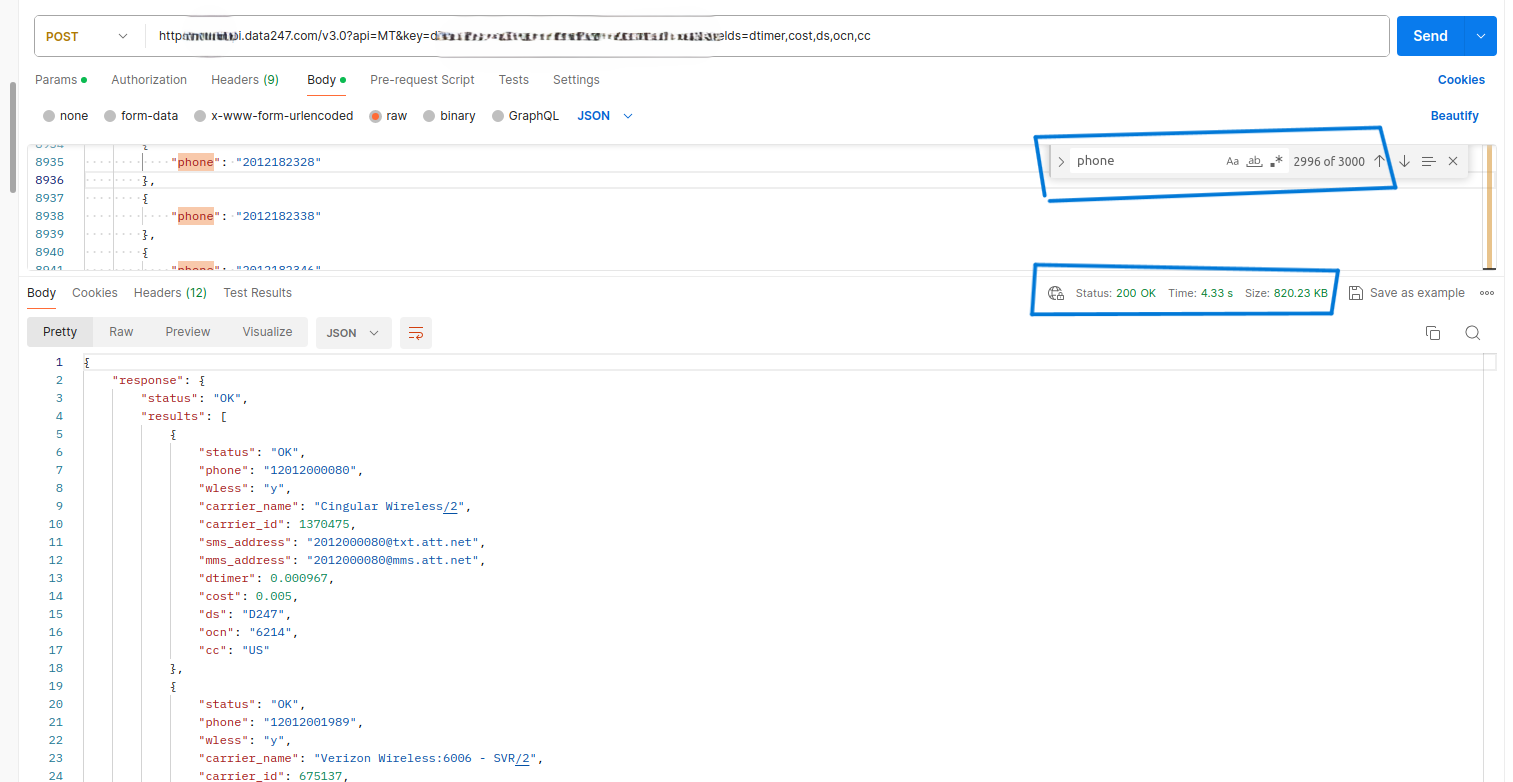
the result
This change led to a dramatic improvement in latency times for some requests – a reduction of over 45%! By cleverly splitting up the workload with asyncio.gather(), we made our bulk requests even more efficient.